Video and Image Captioning Reading Notes
Zhankui He / 15 Mar 2018
Imagine AI in the future, who is able to understand and extract the visual information of the real word and react to them. That’s a grand prospect, and Vision Captioning is one step for it.
Automatically describing the content of an image or a video connects Computer Vision (CV) and Natural Language Processing (NLP). Nowadays, many papers show that the encoder-decoder architecture of models from NLP inspired the Captioning task.
I plan to follow some papers on this area especially about Deep Learning in chronological order, and record my reading and thinking in this blog.
Image Captioning
The task of image captioning is that given image $I$ as input, maximize the likelihood $p(S|I)$ of producing a target sequence of words $S = {S_1, S_2, …}$ where each word $S_t$ comes from a given dictionary describing the image adequately.
There are some papers about that based on encoder-decoder architecture.
1. Show and Tell: A Neural Image Caption Generator (CVPR2015)
Key Idea: Use a deep recurrent architecture(LSTM) from Machine Translation to generate natural sentences describing an image.

This idea is natural and laconic, because the architecture is very similar with the design of standard seq2seq model. The difference between them above is the stage of encoding, where we use CNN to extract the information from images instead of using RNN to encode the text sequence.
Contributions: This paper prospose the powerful encoder-decoder model.
Architecture: End-to-end CNN+RNN model which makes it possible to keep track of the objects that have been explained by the text. The sub-networks are the best ever.
Performance: Use the powerful RNN network LSTM, and provide the visual input directly, to improve the results. There is the BLEU-1 results.
| Approach | PASCAL | FLICKR 30K | FLICKR 8K | SBU |
|---|---|---|---|---|
| SOTA | 25 | 56 | 58 | 19 |
| NIC | 59 | 66 | 63 | 28 |
| Human | 69 | 68 | 70 |
Metrics:BLEU is not a perfect metric after comparing with human evaluation.
Others: Feeding the image at each time step as an extra input yields inferior results, as the network can explicitly exploit noise in the image and overfits more easily.
Further Work:
- Maybe some mechanisms from machine translation and dialogue systems will make sense in image captioning.
- It’s important to propose a new metric to evaluation the quality of sequence generation.
2. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention (JMLR 2015)

Key Idea: Inspired by the attention mechanism in machine translation and object detection, train a ‘soft’ and ‘hard’ attention to distill the important information from images automatically.
Some Details: Hard and Soft Attention. According to the results form experiments, Hard-Attention is better than Soft. But the soft one is smooth and differentiable.
1. Hard Attention:
A stochastic method to maximize the lower bound $L_s = logp(y|a)$, where $a$ is the feature of given image, and $y$ is the ground truth of sequence of words. The gradient is:
where $W$ is the parameters of attention and $s$ is the location variable to decide where to focus attention on. As we know, $s$ is discrete, so this paper approximates this gradient by a Monte Carlo Method, sampling a sequence of attention locations.
The learning rule for hard attention is equivalent to reinforce learning rule.
2. Soft Attention(?):
Take the expectation of tyhe context vector $\hat{z}_t$ directly:
The whole model is smooth and defferentiable under the deterministic attention, so learning end-to-end is trivial by using standard back propagation.
Contributions: This paper prospose the powerful attention model.
Architecture: End-to-end Attention model to distill the rich and important information from images. Add two attention mechanisms on it.
Performance:
| Dataset | Model | BLEU-1 | BLEU-4 | METEOR |
|---|---|---|---|---|
| NIC | 63 | |||
| FLICKR | Log Bilinear | 65.6 | 17.7 | 17.31 |
| 8K | Soft-Attention | 67 | 19.5 | 18.93 |
| Hard-Attention | 67 | 21.3 | 20.30 | |
| MS Research | 20.72 | |||
| NIC | 66.6 | 20.3 | ||
| COCO | Log Bilinear | 70.8 | 24.6 | 20.03 |
| Soft-Attention | 70.7 | 24.3 | 23.90 | |
| Hard-Attention | 71.8 | 25.0 | 23.04 |
Further Work: For my opinion, the dilemmas on encoder-decoder architecture of captioning are that:
- Encoder: The image information is not represented well (Show and tell: use GoogLeNet; this paper: use attention mechanism), so we can explore more efficient mechanism on visual attention, or apply other powerful mechanism to represent the images.
- Decoder: The LSTM text generator may need to be improved, by using other mechanism like GRU, other design other generator to extract information from image representation. More over, the metric to optimize and evaluate the text generator like BLEU is not perfect.
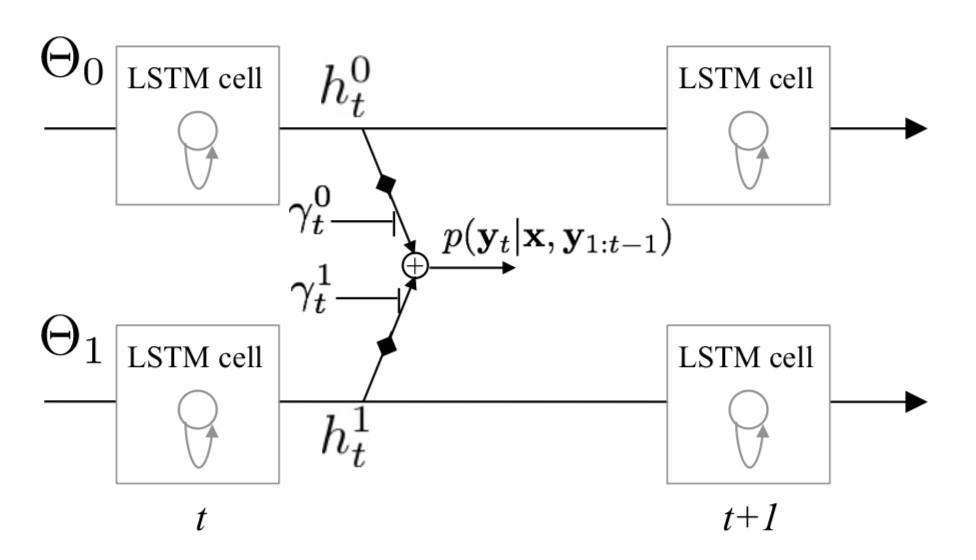
3. SentiCap: Generating Image Descriptions with Sentiments (AAAI 2016)
Key Idea: Generate captions with positve or negative sentiments. This model consists of two parallel RNNs – one represents a general background language model; another specialises in descriptions with sentiments. Use word-level regularizer to emphasize the sentiment words during training and to optimally combine the two RNN streams (Section 3).
The Key idea is the switching RNN for stentiment:
Video Captioning
1. Hierarchical Recurrent Neural Encoder for Video Representation with Application to Captioning (CVPR 2016)
Key Idea: Divide a long video into a few short frame chunks (?what method to use to split the video into chunks automatically?), using LSTM to learn the representation of them, and use other LSTM encoder to learn the ralationship and high-level information from these LSTM output of chunks. That architecture is hierachical.
Use two level of LSTM encoders to learn the local and global information for videos.

I think this example given in this paper can explain the motivation clearly:
Suppose a video of birthday party consists of three actions, e.g., blowing candles, cutting cake, and eating cake. As the three actions usually take place sequentially, i.e., there are strong temporal dependencies among them, we need to appropriately model the temporal structure among the three actions. In the meantime, the temporal structure within each action should also be exploited. To this end, we need to model video temporal structure with multiple gran- ularities.
Contributions: The architecture is similar with a hierachical LSTM auto-encoder in Natural Language Generation and Summarization by Jiwei Li.

Performance: Outperformed (?but is not the best on MSVD with fusion?) the state-of-the-art results on MSVD
| Model | METEOR | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 |
|---|---|---|---|---|---|
| LSTM-E | 29.5 | 74.9 | 60.9 | 50.6 | 40.2 |
| p-RNN | 31.1 | 77.3 | 64.5 | 54.6 | 44.3 |
| HRNE | 32.1 | 78.4 | 66.1 | 55.1 | 43.6 |
| HRNE+Att | 33.1 | 79.2 | 66.3 | 55.1 | 43.8 |
and M-VAD respectively(BLEU metric on this dataset is close to 0! But we can compare with others by BLEU to show the improvement?) :
| Model | METEOR |
|---|---|
| SA-GoogLeNet+3D-CNN | 5.7 |
| SA-GoogLeNet+3D-CNN (different tokenization) | 4.1 |
| S2VT-RGB(VGG) | 6.7 |
| HRNE | 5.8 |
| HRNE + Attention | 6.8 |
2. Improving Interpretability of Deep Neural Networks with Semantic Information (CVPR 2017)
Key Idea:
Improve the interpretability of Deep Neural Networks. The siganificance of interpretability from this paper is:
Interpretability of deep neural networks (DNNs) is essential since it enables users to understand the overall strengths and weaknesses of the models, conveys an understanding of how the models will behave in the future, and how to diagnose and correct potential problems. By clearly understanding the learned features, users can easily revise false predictions via a human-in-the-loop procedure.
by leveraging the rich semantic information embedded in human descriptions.
The gap is that there still lack interpretation techniques for more complex architectures that integrates both CNN and RNN, in which the learned features are difficult to in- terpret and visualize.
Details:
-
Extract a set of semantically meaningful topics from the corpus using Latent Dirichlet Allocation (LDA).
-
Parse the descriptions of each video to get a latent topic representation, i.e., a vector in the semantic space.
-
Integrate the topic representation into the training process by introducing an interpretive loss, which helps to improve the interpretability of the learned features.
The Interpretive Loss is:
where $f: D_v \rightarrow N_t$ is an arbitrary function mapping video features to topics, and $V={v_1,…,v_n}$ is the hidden features from an encoder network. And the topic representation in this paper is denoted as $s$.
As for me, the work on interpretability area is not familiar. So there are no more comments, but I think to open the black box of Deep Learning is really cool.