Text Sentiment Analysis Reading Notes
Zhankui He / 25 Mar 2018
Opinion and Emotion Mining are classic tasks, which are included in Sentiment Analysis. The survey clearified the definitions of Opinion and Emotion, and demonstrated methods and resources about this task.
Definitions
- Sentiment Analysis: mining opinions, sentiments, and emotions based on observations of people’s actions that can be captured using their writings, facial expressions, speech, music, movements, and so on.
- Emotion: discrete and consistent responses to internal or external events that have a particular significance for the organism; emotion has short-term duration.
- Feeling: a subjective representation of emotions, private to the individual experi- encing them; similarly to emotion, it has short-term duration
- Mood: a diffuse affective state that compared to emotion is usually less intense but with longer duration
- Affect: an encompassing term used to describe the topics of emotion, feelings, and moods together.
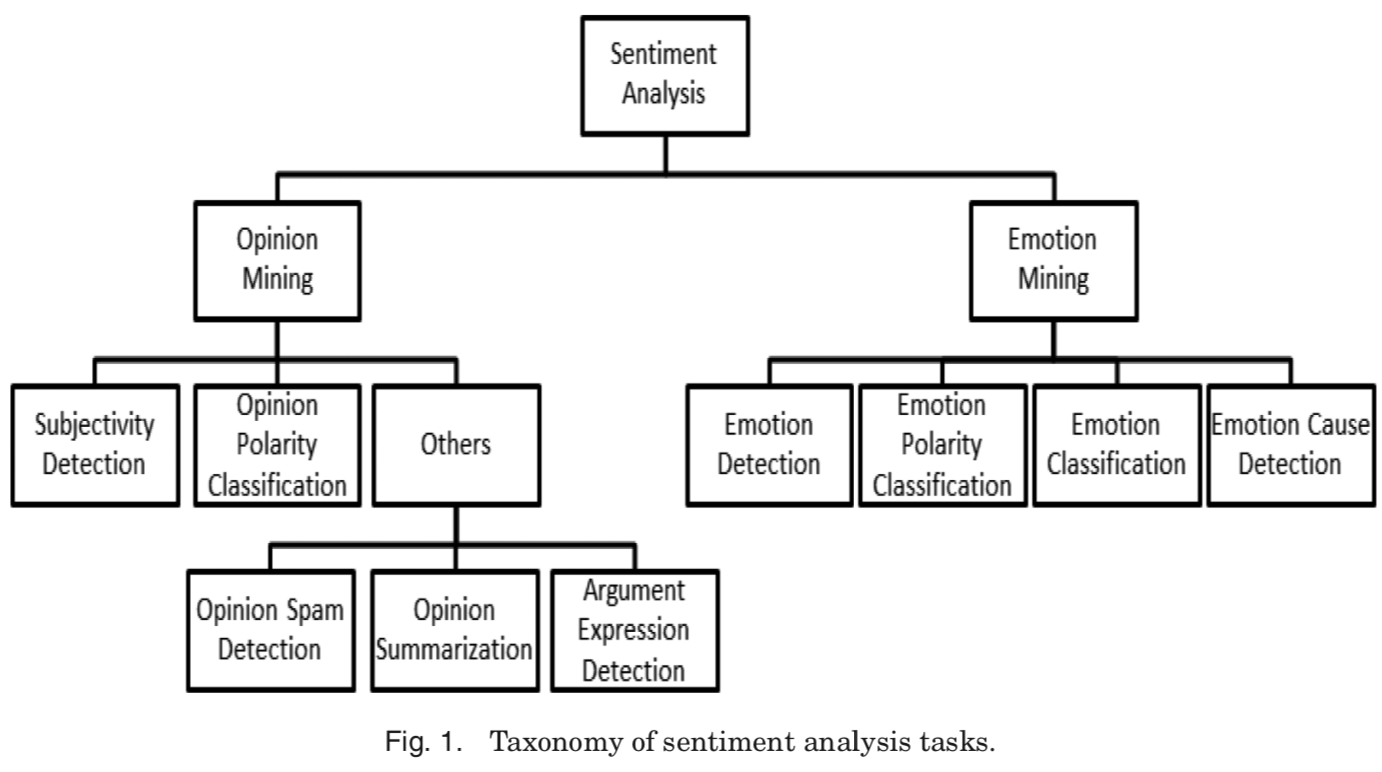
Levels of Classification
- Document Level: In this category, the whole document, whether short or long, is the atomic unit of input to the problem, and the polarity of the whole document is the essence of the study. The simplest sentiment analysis task
- Sentence Level: The objective of this group of studies is to determine the polarity of a sentence. The surrounding context is important.
- Aspect Level: This category, also known as feature-based opinion mining, encom- passes the study of discovering opinion polarities about a specific aspect of a product or service.
Supervised Methods
-
General-perpose Machine Learning: SVM, Naive Bayes, etc.
-
Representation Learning: RNN and CNN in Deep Learning
-
Feature Engineering:
- Presence-Based and Frequency-Based Features.
- Unigram and N-Gram Features.
- Part of Speech.
- Syntax.
- Negation.
- Topic-Oriented Features.
Unsupervised Methods
-
Lexicon Expansion: A lexicon is a dictionary of words, each word associated with a score showing its degree of polarity. However, to have higher performance, one may need to create his/her own lexicon of words suitable for the domain in question.
Lexicon Expansion is build a lexicon automatically, including “corpus-based lexicon expansion”, “dictionary-based lexicon expansion”.
-
Domain Adaptation: adapting the classifier trained over the source to be useful for the target. That is conducted by two steps: Clustering feature and Alignment
-
Other Methods:
- Bootstrapping: The general idea is to use an initial pre-trained classifier on another dataset to label the target dataset and then use this newly labeled dataset to train a new classifier.
- Belief Network Modelling
- Combing lexical and machine-learning methods: Lexical and learning meth- ods can be combined to compensate the disadvantages and drawbacks of each other.